
SEOで重要なクローリングのためのWebパフォーマンス
インデクシングされなければ検索されない
2019年4月17日
著者: 竹洞 陽一郎
多くの人々が、ユーザがGoogleの検索した時に、自社サイトのページがどれくらいの順位で表示されるのかを気にしています。
そのために、SEO(Search Engine Optimization:検索エンジン最適化)に取り組んでいます。
検索順位のランキングで優位に立つために、Webパフォーマンス(表示速度)に取り組む人々も増えてきました。
しかし、多くの人々は、SEO以前の問題として、Webパフォーマンス(表示速度)の中でも、HTMLのレスポンス時間が遅いとクローリングされない問題を認識していません。
まずは、HTMLを100msぐらいで送出できなければいけないのです。
今回は、SEOの施策としてのWebパフォーマンス(表示速度)対策より、検索エンジンにインデクシングされるためのWebパフォーマンス(表示速度)対策が如何に重要であるかを解説します。
HTMLのレスポンス時間の重要性
自社サイトのWebページが、Googleによってインデクシングされるためには、クローリングされなくてはいけません。
インデクシングとは
インデクシングとは、WikipeidaのSearch engine indexingで、以下のように解説されています。
Search engine indexing collects, parses, and stores data to facilitate fast and accurate information retrieval.
Index design incorporates interdisciplinary concepts from linguistics, cognitive psychology, mathematics, informatics, and computer science.
An alternate name for the process in the context of search engines designed to find web pages on the Internet is web indexing.(検索エンジンのインデクシングは、高速且つ正確に情報取得する手助けとして、収集、解読、データを保存する。
インデックスの設計は、言語学、認知心理学、数学、情報学、コンピュータサイエンスなどの異なった学問分野の概念に立脚している。
インターネット上のWebページを探し出すための検索エンジン設計の絡みにおける処理の名称としては、Webインデクシングと呼ばれる。)
クローリングとは
クローリングとは、weblio辞書のクローリングで、以下のように解説されています。
クローリングとは、ロボット型検索エンジンにおいて、プログラムがインターネット上のリンクを辿ってWebサイトを巡回し、Webページ上の情報を複製・保存することである。
クローリングを行うためのプログラムは特に「クローラ」あるいは「スパイダー」と呼ばれている。
クローラが複製したデータは、検索エンジンのデータベースに追加される。
クローラが定期的にクローリングを行うことで、検索エンジンはWebページに追加・更新された情報も検索することが可能になっている。
John Muller氏の発言
2018年9月7日のGoogle Webmaster Central office-hours hangoutで、GoogleのJohn Mueller氏は以下のように述べています。
動画の再生ボタンを押した後に、字幕のボタンを押すと、英語の字幕が出ます。
One way you can kind of estimate if this is the case is to go into search console into the crawling stats to see the number of pages that we crawl per day that gives you a little bit of idea where you can guess is this about reasonable or not.
And another thing you can see there is the response time so the time took on average for a page to respond.
That's not the same time it takes load a page in browser.So things like PageSpeed Insights don't necessarily play into that but rather just the pure individual requests that we make to the server, would say I want this HTML page or I want this one image or I want this one PDF file and on average the time that it takes to get that information back.
And it's hard to give any kind of guideline on what number you should be aiming for there, but generally speaking I decides I see that are easy to crawl tend to have response times there of maybe a hundred millisecond and to five milliseconds something like that.
If you're seeing times that are over a thousand milliseconds so that's over a second profile not even to load the page then that would really be a sign that your server is really kind of slow and probably that's one of the aspects it's limiting us from crawling as much as we otherwise could.(自分のサイトに1日あたり何ページクロールされているのかをSearch Consoleのクローリングの統計で確認して、その数が理に叶っているかどうかを確認するというのは、このケースに当てはまっているかどうかを推測する方法ですね。
そして、もう一つ、ページが返ってくるまでの平均時間であるレスポンス時間を確認できますよね。
これはブラウザ上でページを読み込むのに掛かる時間と同じではないです。ですからPageSpeed Insightsで調べる必要はなくて、サーバにリクエストを個々に送った時の純粋な時間の方です。
例えば、このHTMLページが欲しいとか、この画像が欲しいとか、このPDFファイルが欲しいといった、情報を入手するための平均時間です。
ここではどのくらいの秒数を目指すべきかというガイドラインみたいなものは一切言えないのですが、一般的に、大体100~500msぐらいのレスポンス時間であればクローリングしやすいと確信しています。もしもあなたが確認したとき、その時間が1000msを超えているということは、ページの読込は1秒以上掛かっているということですから、それは本当にあなたのサーバは遅い部類に属しているという兆候です。
本来、私達がクローリングできるページ数を制限している一つの要因でしょう。)
HTMLのレスポンス時間が100~500msであればクローリングしやすく、1000ms(1秒)以上掛かった場合には、クローラーがタイムアウトする可能性を示唆したのです。
HTMLのレスポンス時間とは
全てのWebページは、そのファイルが拡張子が何であれ、HTML(Hyper Text Markup Language)で記述されています。
HTMLは、Webページに表示される実際のデータとその文書構造を一緒に記載した設計図と言えるでしょう。
このHTMLの記載に基づいて、Webブラウザは、CSSファイルやJavaScriptファイル、画像、動画などをダウンロードして、ページを構築します。
この作業は、ユーザがページ遷移をする都度、毎回行われるという点に注意して下さい。
その事が、従来のソフトウェア工学と、Webサイトのソフトウェア工学の大きな違いとなりました。
従来のソフトウェアは、コーディングして、デバッグして、コンパイルしてしまえば、制品として状態が保持されるのに対して、Webサイトの場合は、要求される毎に、部品を組み立てている工場のラインのようになってしまったのです。
Webブラウザから、HTMLを要求されて、それを送出するまでの時間を、「HTMLのレスポンス時間」と言います。
HTMLのレスポンス時間は、以下のネットワークコンポーネントの合算値となります。
- DNS Lookup
- ページのドメイン名(例えば、perfdata.jp)は、インターネットのネットワークアドレスとしてはどこにあるのかを問い合わせる処理。
- TCP Connection
- インターネットのアドレスが判明したら、そこまでの接続を確立する処理。TCP 3way handshakesと呼ばれる処理が行われる。
- SSL Negotiation
- WebサーバとWebブラウザ間で、SSL(正式にはTLS)で暗号化してデータを送受信するための前処理。
- Send
- Webブラウザから、Webサーバに対して、ファイルを要求する処理。GETリクエストやPOSTリクエストなどがある。
- Wait
- WebサーバがHTMLを記載したファイルを送出するまでの待機時間。動的にHTMLを生成する場合には、この時間が長くなる。
- Loading
- HTMLを記載したファイルの最初から最後までを送信し終えるまでの時間。
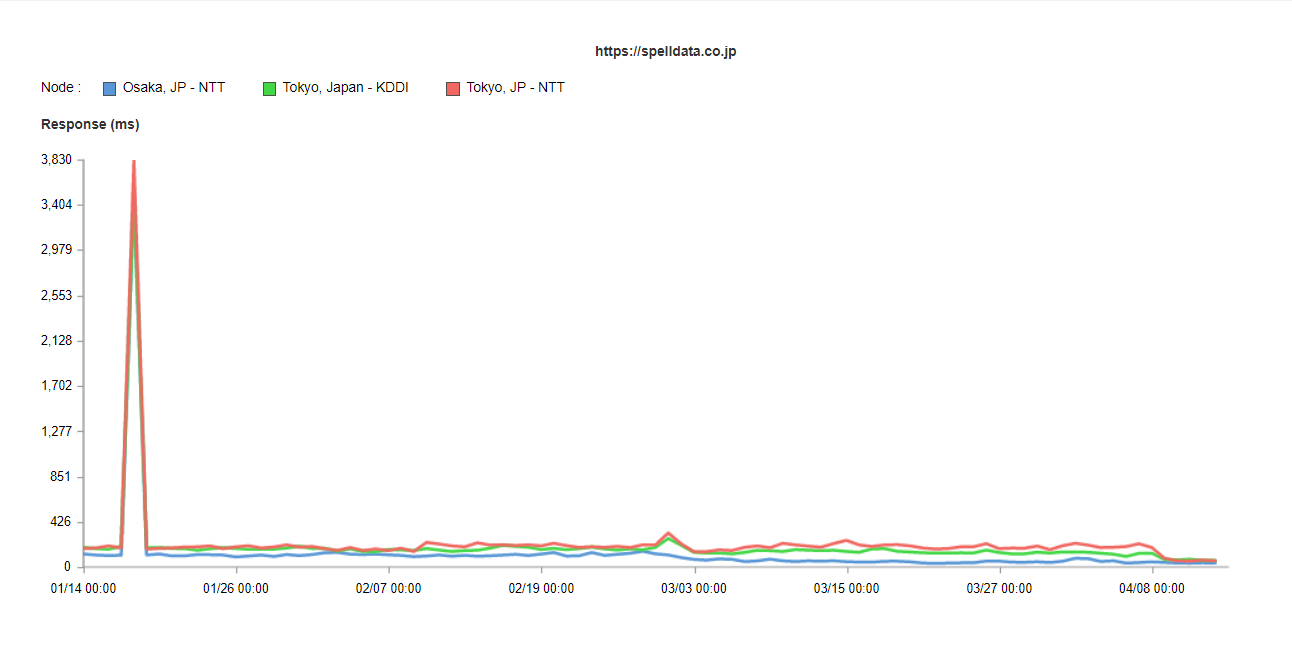
perfdata.jpのindex.htmlのレスポンス時間は、以下のようなグラフとなります。
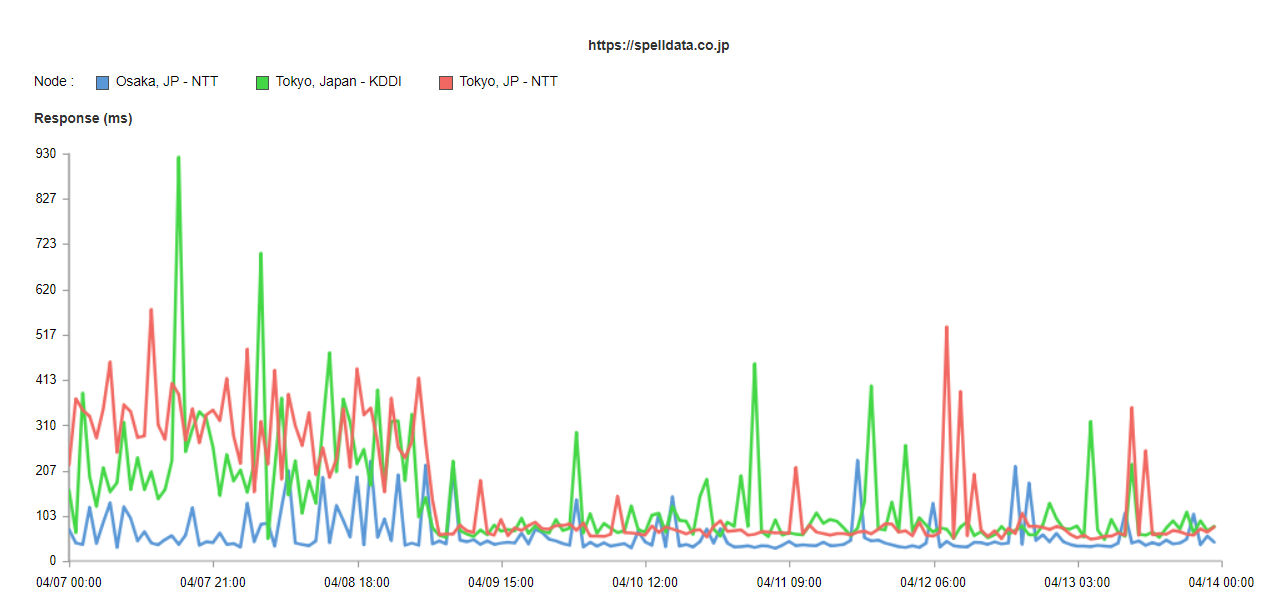
このグラフを、一週間の累積分布関数で表示して、一週間の品質として見ます。
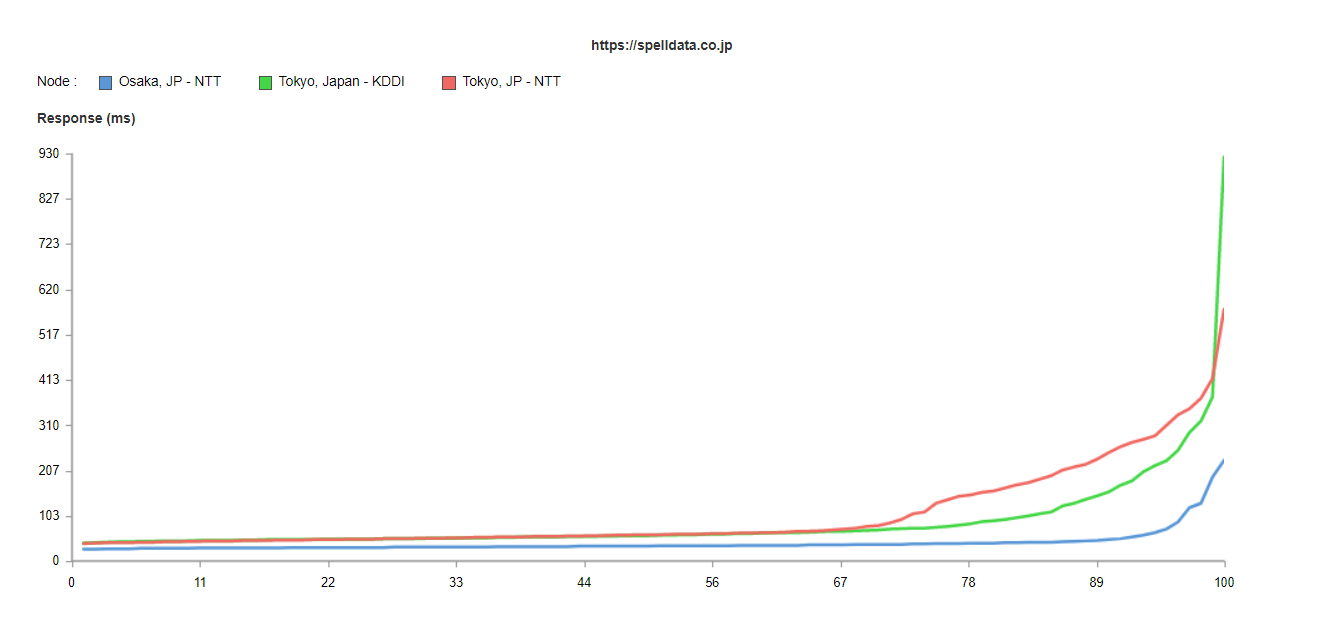
67パーセンタイルを超えたあたりから、急激に、東京のNTTと東京のKDDIで遅延しているのが分かります。
これを、各ネットワークコンポーネントに分解してみましょう。
すると、Wait(待機時間)が主たる遅延要因であることが分かります。
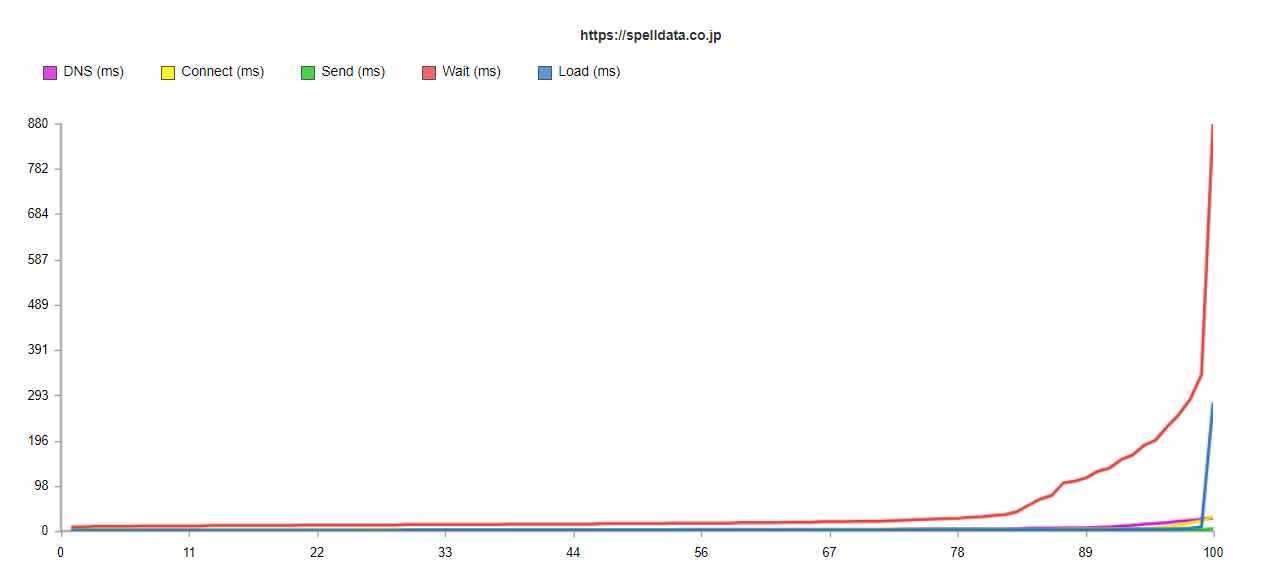
SEOのためにWebパフォーマンス(表示速度)を気にされる方は、画像やJavaScriptの処理などに気を取られがちですが、そもそも、HTMLが遅延すると、インデクシングされない可能性が高いという点に注目して欲しいのです。
クローラーのHTMLレスポンス時間を確認する
それでは、Googleのクローラーは、どの位の時間でHTMLを取得できているのでしょうか?
上述のGoogleのJohn Mueller氏は、その確認方法を述べていました。
そして、もう一つ、ページが返ってくるまでの平均時間であるレスポンス時間を確認できますよね。
旧版のGoogle Search Consoleのクロールの統計情報で、それを確認することができます。
下の画像の、水色枠で囲っている場所です。
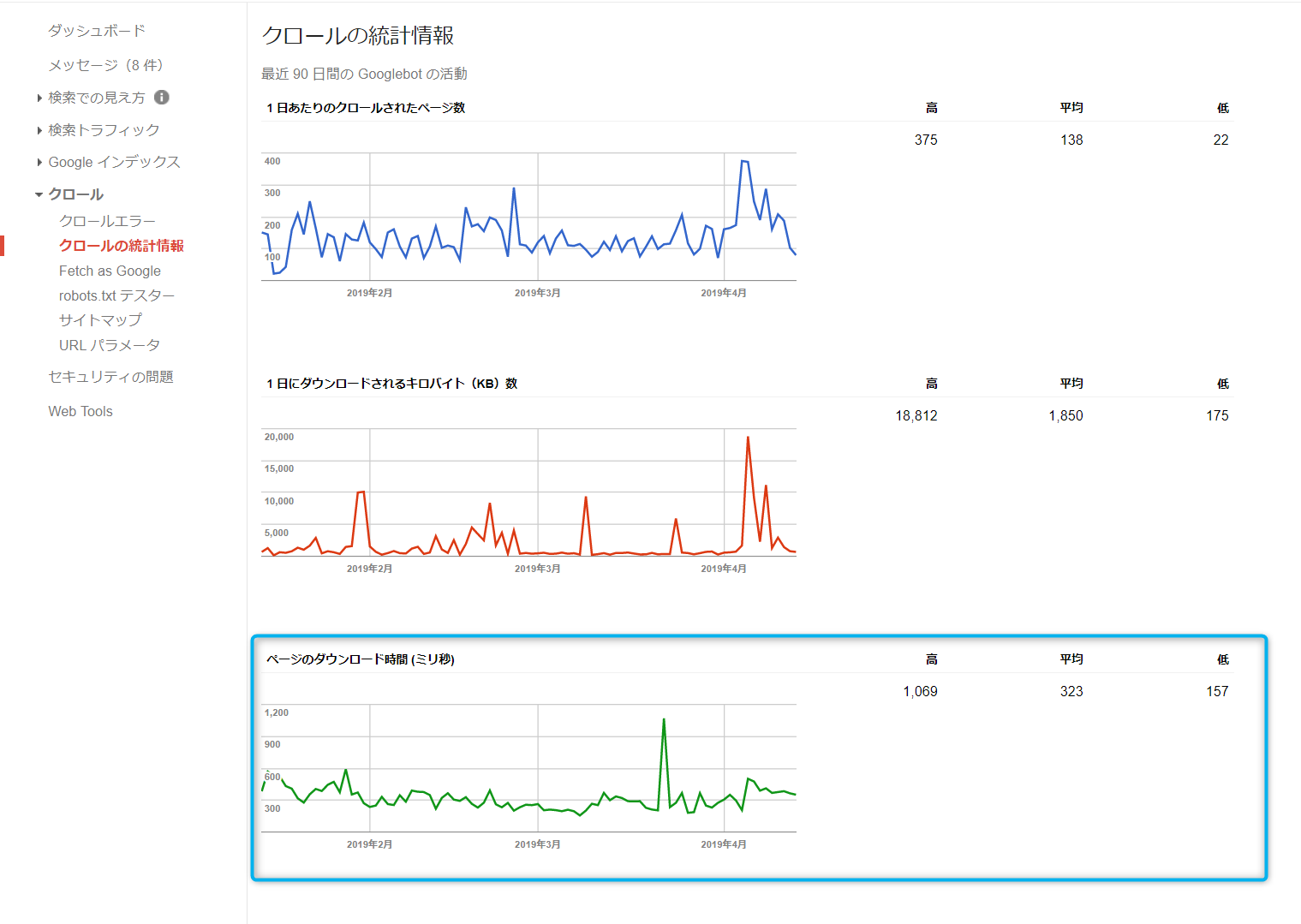
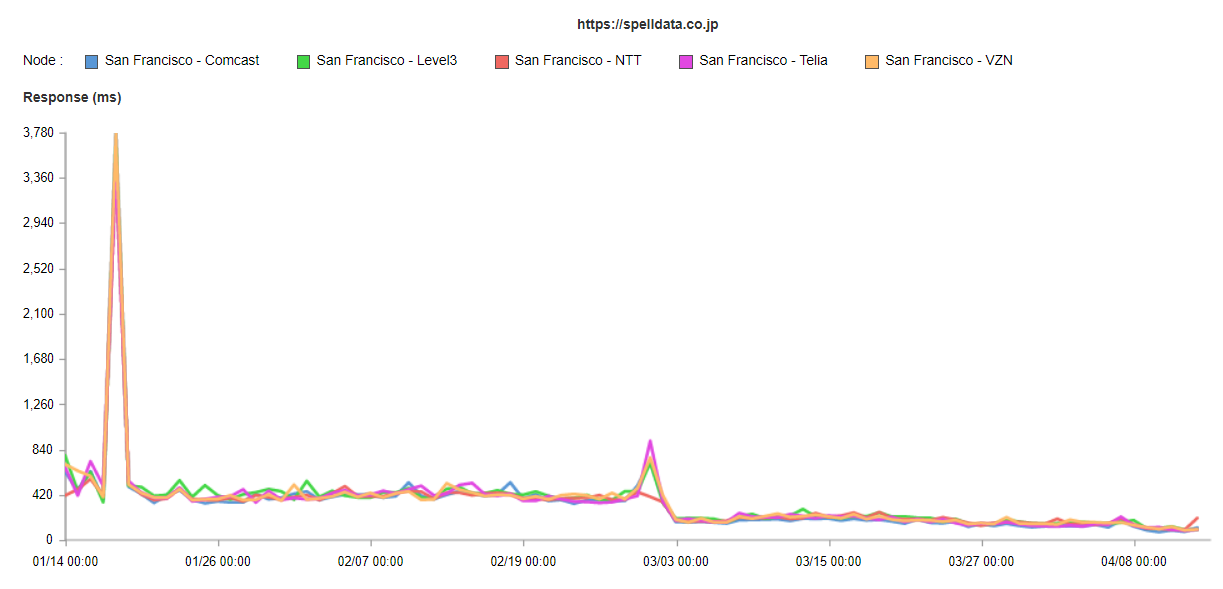
これを日本のISPでの計測と比べてみましょう。
どうも、日本でのISPのindex.htmlのダウンロード時間とは違うようです。
クローラーはアメリカからやってくる
何故、日本でのindex.htmlのダウンロード時間と、Google Search Consoleでの時間が異なるのでしょうか?
その理由は、「クローラーは、99%、アメリカからやってくる」からです。
("Google AdBot and google Bot - Are they crawling from US?")
ですから、上述の「HTMLが100~500msで送信されれば」というのは、日本ではなく、アメリカでという事になります。
アメリカ・サンフランシスコのISPでの計測と比べてみましょう。
しかし、これよりも、Google Search Consoleの値は遅いです。
では、実際のところ、アメリカのどこからGoogleのクローラーはやってくるのでしょうか?
Stackoverflowへの2013年の投稿で、ちょっと古いのですが、それを調べた人がいます。
("Where does Googlebot crawl from?")
調査内容は、バージニア州にあるAWSのWebサーバに来たGoogle BotのIPアドレスをMaxMindのデータベースで調べて場所を特定したというものです。
MaxMindは、非常に精度の高いIPからロケーションを特定できるデータベースを提供しています。
Spelldataでも、有料版を使用しています。
(とは言っても、常に100%正しいロケーションというわけではないです。IPから場所を特定するデータベースは複数利用するのが鉄則です。)
この方によると、以下のような分布となるそうで、2014年3月の時点での観測です。
- Illinois (46.35%)
- Arizona (15.68%)
- Wisconsin (14.95%)
- Virginia (11.85%)
- California (11.17%)
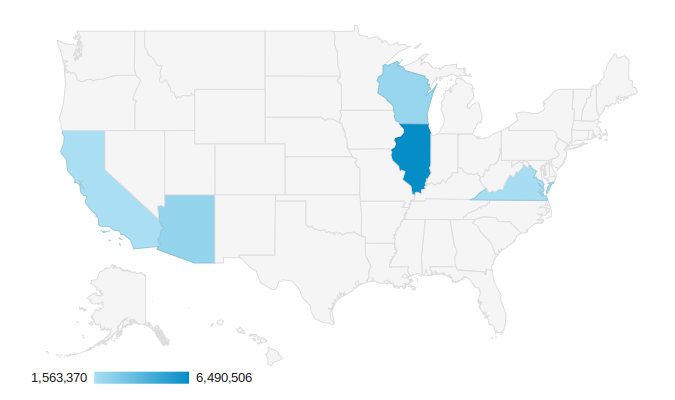
("Where does Googlebot crawl from?"から転載)
シカゴのあたりからGoogle Botがやってくるとなれば、確かに、サンフランシスコより遅いですよね…
まとめ
Spelldataのindex.htmlは、国内であれば50~100msでダウンロードできますが、それがGoogle Botがやってくるアメリカでは300~600msになります。
国内でHTMLのレスポンス時間が200msを超えたら、クローラーがタイムアウトする確率が非常に高くなるというのは知っておかれると良いかと思います。
この件については、弊社のお客様でも検証済みです。
さて、新版のGoogle Search Consoleには、ページレスポンス時間を確認する画面が無いのですが、どうしたものでしょうかね?
Spelldataでは、Catchpointで、アメリカでの計測をお手伝いできます。