
Webブラウザのもう一つのパーサ: Preload Scanner
高速化の秘密兵器!WebブラウザのPreload Scannerを活用して高速化しよう!
2023年5月1日
著者: 竹洞 陽一郎
はじめに
Do it once. Do it right. And, you'll never have to do it again.
一度だけやれ。正しくやれ。そうすれば二度とやらずに済む。
詠み人知らず
前回の記事では、HTMLのDOMツリー構築について解説しました。
DOMツリー構築では、一気呵成に、1行目から最後の行までパースできるのがベストです。
しかし、往々にして、途中の行で止まってしまうのをプロファイリングデータで見かけたことはありませんか?
今回は、そのようなDOMツリー構築を邪魔する処理となる、CSS、JavaScript、画像などの読込をバックグラウンド処理にしてくれる「Preload Scanner」について解説します。

Preload Scannerとは?
Preload Scannerは、WebブラウザがページのHTMLを浅く解析(Shallow Parsing)しながら、リソース(画像、CSS、JavaScriptなど)をバックグラウンドプロセスで読み込む、もう一つのパース機能です。
これにより、ブラウザがメインスレッドの時間を消費せずに必要なリソースを読み込み、ページ表示にかかる時間を短縮することができます。
これは、HTML Living Standardに仕様が定められているわけではなく、Webブラウザの独自実装です。
| ブラウザ | 対応開始バージョン | リリースした年 |
|---|---|---|
| Chrome | 1 | 2008 |
| Firefox | 3.5 | 2009 |
| Safari | 5 | 2010 |
| Internet Explorer/Microsoft Edge | 11 | 2013 |
Firefoxでは、Preload Scannerという呼称ではなく、Speculative Parserと呼称されています。
Shallow Parsing
Preload Scannerは、Shallow Parsing(浅いパース処理)という手法を使います。
Shallow Parsingとは、文法解析の一種であり、構文解析の表層的なレベルで行われる解析手法です。
Shallow Parsingは、文法構造を完全に解析する深層解析(Deep Parsing)とは異なり、文書やコードの全体的な構造を理解しようとはせず、特定の情報やパターンを効率的に抽出することに焦点を当てています。
WebブラウザのPreload Scannerにおいては、Shallow ParsingがHTMLドキュメントの表層的な構造を迅速に解析する役割を担っています。
Preload Scannerは、HTMLの解析を待たずにリソース(画像、スクリプト、スタイルシートなど)の情報を抽出することを目的としているため、Shallow Parsingが適切な手法となります。
Shallow Parsingの特徴は以下の通りです。
- 速度
-
Shallow Parsingは、深層解析に比べて高速に実行できます。
これは、文書全体の構造を理解する必要がなく、特定の情報を抽出するだけでよいためです。 - 簡易性
-
Shallow Parsingでは、単純なルールや正規表現に基づいて情報を抽出することが一般的です。
そのため、実装が容易であり、複雑な文法構造を扱わなくてもよいという利点があります。 - 柔軟性
- Shallow Parsingは、完全な文法解析が不要であるため、文書やコードの構造が不完全であっても、特定の情報を抽出することができます。
ただし、Shallow Paringは、文書やコードの全体的な構造を解析しないため、文法的な正確さや意味的な理解が得られないことが欠点となります。
そのため、Shallow Parsingは、特定の目的に応じた効率的な情報抽出手法として利用されます。
Shallow Parsingが使わている他の実装例
Shallow Parsingは、効率的に特定の情報やパターンを抽出するために用いられる手法であり、Preload Scanner以外のさまざまな分野やアプリケーションで利用されています。
以下に、Shallow Parsingが使われるいくつかの例を挙げます。
- 検索エンジン
-
検索エンジンのクローラーは、Webページから特定の情報(メタデータ、キーワード、リンクなど)を効率的に抽出するために、Shallow Parsingを利用します。
深層解析を行うよりも高速で、構造が不完全なページでも情報を取得できるため、クローラーが大量のWebページを効率的に処理するのに適しています。 - テキストマイニング
-
自然言語処理(NLP)やテキストマイニングにおいて、Shallow Parsingは、名詞句や動詞句などの簡単な構造を抽出するために使われます。
これにより、文書内の主要な情報やキーワードを効率的に抽出し、文書の分類や要約などのタスクを行うことができます。 - コードエディタやIDE(統合開発環境)
-
Shallow Parsingは、コードエディタやIDEにおいて、シンタックスハイライトやインデントの自動整形、コードの概要表示などの機能を実現するために使われます。
深層解析よりも高速で、コードの一部が欠けていても機能するため、リアルタイムでのコード解析に適しています。
これらの例からわかるように、Shallow Parsingは、様々な分野で効率的な情報抽出が求められる場面において幅広く活用されています。
Preload Scannerの仕組み
Preload Scannerは、HTML解析の初期段階で動作を開始します。
この段階では、ブラウザはまだページ全体の構造やデザインを理解していませんが、リソースへのリンクを見つけることができます。
Preload Scannerは、これらのリンクを見つけ次第、リソースの読み込みを開始します。
この先読み動作は、ページの表示が遅延されることなく、バックグラウンドで実行されます。
そのため、ページが表示されるまでの時間が短縮され、ユーザーがよりスムーズな閲覧体験を得ることができます。
Preload Scannerは、ページ上のリソースを効率的に先読みするために、さまざまなHTMLタグをチェックしています。
主な対象となるHTMLタグは以下の通りです。
- <link>
- スタイルシートやファビコン、プリロードされるべきリソースを指定するために使われます。
- <script>
- JavaScriptファイルを読み込むために使われます。
- <img>
- 画像ファイルを表示するために使われます。
- <audio>
- オーディオファイルを再生するために使われます。
- <video>
- ビデオファイルを再生するために使われます。
- <source>
- <audio>や<video>タグの中で使われ、代替フォーマットのメディアファイルを指定するために使われます。
- <iframe>
- 他のHTMLページを埋め込むために使われます。
- <object>
- 外部リソースやプラグインコンテンツを埋め込むために使われます。
- <embed>
- 外部リソースやプラグインコンテンツを埋め込むために使われます。
これらのタグをチェックすることで、Preload Scannerはページで使用されるリソースを効率的に先読みし、ページの読み込み速度を向上させることができます。
ただし、ブラウザの実装やバージョンによって、チェックされるタグや仕様が異なる場合があります。
Preload Scannerのメリット
Preload Scannerには、以下のメリットがあります。
- HTMLのパース処理の中断を防ぐ
-
CSSやJavaScript、画像などをバックグラウンド処理でダウンロードすることで、HTMLのパース処理の中断を防ぎます。
これによって、一気呵成にDOMツリー構築を終了させることが可能となります。 - 並列処理化
-
ブラウザはシングルスレッドであることは、皆さんもよくご存じでしょう。
Preload Scannerで読み込まれるCSSやJavaScript、画像は、バックグラウンド処理が立ち上がって、そちらでダウンロードされるので、メインスレッドを邪魔しないのです。
Chromeなどではプロセス数が増えるのが確認できます。
マルチコアプロセッサやマルチプロセッサシステムにおいて、異なるコアやプロセッサがそれぞれ独立したタスクを同時に処理する方法を並列処理化(parallel processing)と呼びます。
並列処理の目的は、処理能力を向上させ、タスクの完了時間を短縮することです。
Preload Scannerの場合は、HTMLのパース処理の時間を有効活用して、その間に別プロセスで各種ファイルをダウンロードすることで、高速化させるのです。 - 開発者の負担軽減
-
開発者は、基本的には、制約事項を守ってコーディングさえすれば、Preload Scannerの恩恵を受けることができます。
こんな便利な機能が10年前に実装されていたのですから、使わない手はありませんよね。

この図において、HTMLのパース処理時間の合計より短くなっている点に注目して下さい。
コンピュータ処理の基本ですが、処理に割り込みが入るほどに、オーバーヘッドが生じて、処理時間が長くなります。
CSSやJavaScript、画像などの読込処理の割り込みが無くなることで、オーバーヘッドが解消されて処理時間が短くなるのです。
コンピュータの計算処理では、ソフトウェアのContext SwitchやハードウェアのInterruptといった割込が遅延を引き起こす原因となります。
高速化は、この割込処理を如何に発生させないようにするかが重要です。
Webブラウザ上の処理も同様で、一つの計算処理を都度中断されるより、答えが出るまで専念させる方が効率が良いのです。
Preload Scannerの注意点と制限事項
Preload Scannerは便利な機能ですが、いくつかの注意点や制限事項も存在します。
- インライン記述に対応していない
-
Preload Scannerは、インライン記述に対応していません。
Preload Scannerは、Shallow Parsingであって、ダウンロードすべきファイルを探すために単なるリソースの文字列を浅く解釈しているに過ぎません。
インラインで記述しているCSSやJavaScriptは、全て、外部ファイル化しましょう。
これは、現在のフロントエンドのセキュリティ対策で重要なCSP(Content Security Policy)を適用する上でも大事なことです。 - クロスオリジンリソースに対応していない
-
Preload Scannerは、セキュリティ上の制約により、クロスオリジンリソースに対しては機能しません。
これは、クロスオリジンリソースが読み込まれる際に、セキュリティの検証プロセスを完了する必要があるためです。
CSSやJavaScriptを安易にCloudflareなどのCDN配信のものを利用すると、Preload Scannerの恩恵を受けることはできません。
自社サイトのWebページで使うCSSやJavaScriptについて、良かれと思ってCloudflareから配信しているものを読み込んでいる方もいるとは思いますが、自社サイトから配信しましょう。
もしくは、CSPで明示的に許可したドメインのリストに入れることでPreload Scannerの処理が有効化されます。 - 依存関係から解放する必要がある
-
JavaScriptをバックグラウンドでダウンロードするには、defer属性を付与します。
しかし、defer属性を付与するということは、DOM Content Loadedの発火のタイミングで実行することを意味しているので、それよりも前に実行される必要がある書き方の場合、defer属性を付けられません。
画像をバックグラウンドでダウンロードするには、decoding="async"を付与します。
しかし、JavaScriptなどと依存関係があると、decoding="async"属性は効かなくなります。 - Deep Parsingが必要な処理は対応できない
-
例えば、<picutre>のようなDeep Parsingを必要とするタグは、decoding="async"のような属性を付与しても、バックグラウンドでダウンロードはしてくれません。
現在の通信環境は、モバイルの4G環境であっても、LTE Advanced Proによって、下り100Mbpsぐらい出ます。
ファイルの軽量化ばかり気にして画像の出し分けをするより、普通に<img>で読み込んで、decoding="async"属性を付与する方が高速です。 - CSSとJavaScriptはhead内に全て記載する
- CSSとJavaScriptは、メタデータですし、Preload Scannerの恩恵を早々に受けるために、head内に書きましょう。
Preload Scannerが効いていない箇所を確認する方法
Chrome Developer Toolsを使ってプロファイルすると、Preload Scannerが効かない箇所が簡単に確認できます。
パフォーマンスタグでプロファイリングデータを取得してみましょう。
そうすると、以下のように「HTMLを解析 「79...87」のような記載が確認できます。
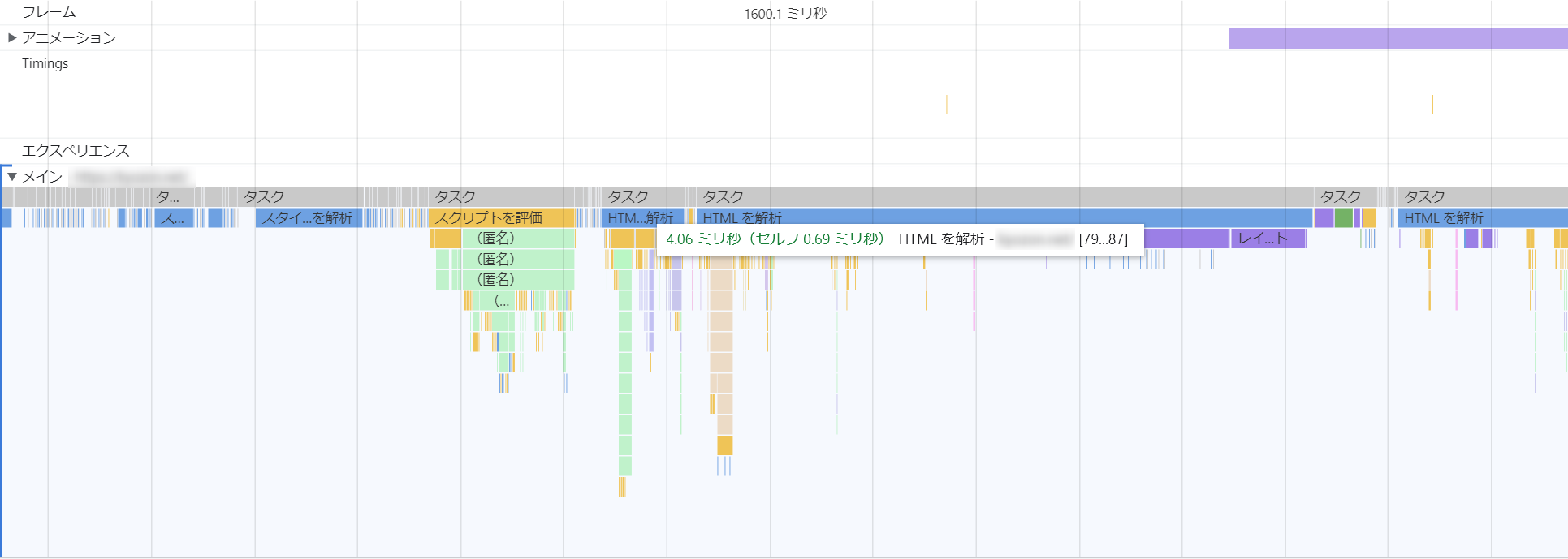
これは、HTMLの78行目までで一旦パースが中断されて、再開して79~87行目までパースして、また中断したことを表しています。
つまり、78行目や88行目にパース処理を中断させてしまった原因があるのです。
その行を確認すれば、上記に挙げたPreload Scannerが効かなくなる制約事項のいずれかが見つかります。
この確認とPreload Scannerによるバックグラウンドでのダウンロード化の作業を、弊社のお客様が「Windowsのデフラグみたいですね」と仰っていましたが、言い得て妙だなと思いました。
フロントエンド周りの高速化は、このように、断片化してしまった処理をまとめることで、オーバーヘッドを減らし、高速化できるのです。
そのためには、Preload Scannerの機能を有効活用する必要があります。
まとめ
WebブラウザのPreload Scannerは、ページの読み込み速度を向上させるための重要な機能です。
開発者は、この機能を理解し、適切に活用することで、ユーザーに最適な閲覧体験を提供することができます。
ただし、パフォーマンスやセキュリティに関する注意点を考慮し、最適なPreload Scannerの活用法を見つけることが重要です。